My latest maker obsession: A low-cost, open-source robotic helper backpack.
Watch the cyborg backpack in action!
Note the pen dropped because I’m really bad at controlling the cyborg arms. I accidentally opened the gripper. It’s not the fault of the system.
Completely controlled with your Android phone and smartwatch! There’s an app for the world of cyborgs!
System Specs:
-2 Dagu 6DOF Arms -SSC32 Servo Controller w/ custom enclosure -Raspberry Pi B w/ portable USB battery and Adafruit Case
-2 Ultrasonic sensors on the sides of the backpack serve to detect obstacles and your phone beeps if you get close to something. This helps you protect the extra arms from damage.
-2 web cams allow you to see behind you. -Tekkeon External Battery for powering the servo controller and rasp pi
The Cyborg Distro is open source: https://github.com/prateekt/CyborgDistro. Feel free to contribute to the codebase! We hope many more humans will join the distro. Our goal is to distro all humans by 2050!
Custom SSC32 Servo Controller Enclosure keeps the controller safe inside of the backpack but still easy to use:
Also, there are many more arms from where this came from:
I used to work on MVLDDB, a database of evidence cards for my high school debate team. In college (the web 2.0 era for me), I contributed design to the Debatepedia effort, a wiki of debate arguments that later become the IDEA Debateabase. In the coming age of Robotics, however, I believe much more is possible. The good folks at IBM have announced plans to build a computer that can think and argue like humans (http://www.techfess.com/2014/05/computer-that-can-think-and-argue-like-a-human-1096/), though they’re not exactly sure how this should work.
I have been considering a related and somewhat much harder problem: building a robot that can argue WITH humans in the context of a debate. This is a problem very near and dear to me, and I have spent many years of my spare time in grad school wondering how exactly to build a debate robot.
A robot participating in a debate goes a step further than something that simply answers questions like Watson to support user queries. A debate robot has to exhibit more autonomy than just answering questions or finding evidence to support user queries. It has to strategically ask questions in the context of having a debate opponent / adversary, learn about the distributions of stock arguments (and responses) from lots of previous case data, and come up with strategic responses to a debate constructive in a set time limit (i.e. only a finite number of responses can be made from the likely larger set of possible responses) to judge. It also has to present arguments in a persuasive manner. In a sense, it really has to follow the Learning, Planning, and Execution methodology of Robotics in addition to question answering.
I believe debate robotics is an important step in the quest for the Turing Test since it would extend Intelligent Robotics from question answering to question asking. If robots could ask good questions via the principles of debate (and maybe also algorithms inspired from the field of journalism which really studies how to ask questions about a scene and understand a scenario really efficiently), they would be able to help us in the search for answers and to do research. I truly believe there is world-changing potential in the construction of a robot debater. The project is hard, though, much harder than anything I have ever actually built, and the theory hasn’t been figured out.
I might have sent this rather ambitious white paper to some of my readers for critique. It is still pretty rough, bare in mind, and there are multiple ways to do it. I am happy to finally make the white paper public so that others can contribute to the discussion. Biggest need at the moment: looking for a good data set of debate cases.
Intrigued? Read on. Is it possible? You be the judge.
Here is the platform we will build algorithms for:
Also, hacked out a speed reading engine for the robots (since the theatrics of robot debate are too much fun): http://debaterserver.co.nf/robot_spreading.wav. Not that it should be used any time soon…
The algorithm exhibits good speed-reading technique with a good word rate that starts slow and accelerates w/ increased judge perceptual focus. Robots/Cyborgs don’t have to breathe, so I had to program in breathing constraints to keep the debate fair. She can already impact to nuclear annihilation, subsequent starvation of the remaining human population, and destruction of the earth’s biosphere at a blazing rate. Sure that you’re still up for the debate?
—–
I. Introduction
Robot Intelligence leaves a lot to be desired today, but it can improve. Robots are becoming more capable every day in driving our cars, helping automate our health care system, helping make our medical procedures safer, and patrolling our forests for poachers. However, if robots are indeed to create an uprising worthy of challenging human authority, they must be able to first disagree and argue with human authority. This blog post proposes designs for an intelligent robotic debater that can refute a debate constructive.
It is important to cite a couple preliminaries. First, this is just one possible design for a robotic debater. Just like people have different debate styles, philosophies, and opinions, it is natural to think that robots will too. Second, what I propose is still fairly limited in scope in AI. My design is a first shot at a possible conceptual prototype of machines that are completely imaginary right now. Nobody knows how to build these things right now, and obviously the design can and will change. My hope is that this will inspire you to think a little and push the boundaries of the science a tad.
II. Problem Statement
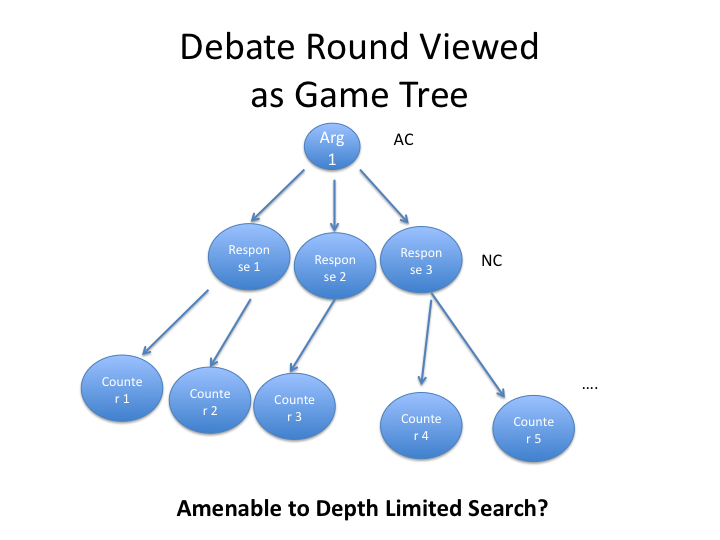
The goal of the system is, given a debate case on a particular topic, provide a refutation speech of that case. In LD debate, that would correspond to generally the refutation portion of the Negative Constructive (NC) that refutes the Affirmative Constructive (AC) or the refutation portion of the 1AR, which refutes the NC. Other debate formats might have fewer or more constructive, which makes the design task complicated so let’s just use LD debate as the primary example.
The generated refutation speech must fulfill a couple constraints:
1. It must be responsive to the arguments in the opponent’s constructive. It must identify what argument the opponent is making, and then provide responses to the speech.
2. The refutation speech must fit within an allotted speech time limit specified by the rules of the debate.
3. The refutation speech must be strategic, that is it must help maximize the chance of the robotic debater eventually winning the round. This is not to say the robot is a cheapskate that prioritizes winning at all cost (there may be additional constraints to avoid ridiculously immoral behavior), but I think it’s fair to say the robotic agent, at minimum, prefers to win rather than to lose.
III. Algorithmic Architecture
The input to the robot is a debate constructive (either an AC or NC). The robot produces a rebuttal speech. Here is a diagram of its components.
(A) The robot has a Case Dissection Algorithm (grounded in intelligent text segmentation and summarization) that summarizes the case into a set of unique arguments.
(B) An Argument Classifier is used to determine which argument the opponent is making (from the set of possible unique arguments on a topic, taking into account different ways of semantically making those arguments).
(C) The robot contains an Argument Knowledgebase of the mapping of arguments to possible responses. Once the robot knows what arguments are on the table, it can assemble a giant list of possible responses to make from its knowledgebase.
(D) A Strategy Engine scores the possible arguments, quantifying their utility in relation to opponent strategies and responses. The strategy engine optimizes several criteria (chances of winning the round, ethics in doing so, etc) but does it in a rigorous game theoretic optimization framework that can scientifically understand the tradeoffs of these factors. The strategy scores are then fed into the Response Scheduler.
(E) The robot has a Response Scheduler to schedule responses. Taking into account the scores of possible responses from the strategy engine, a scheduling algorithm (inspired from load balancing techniques in computer architecture and office scheduling) efficiently finds the subset of responses (from the large space of possible combinations of feasible responses) that are (a) strategic based on the output of the strategy engine (b) fit in the allotted time limit of the speech time and (c) take into account constraints of argument ordering for effective emphasis and processing in cognitive memory of the judge.
IV. Software Component Descriptions
In this section, feasible implementations for the components are described. Many of these are just starter ideas, and are likely to get modified, as the debate robot problem is better understood scientifically.
Case Dissection Algorithm
The role of the Case Dissection algorithm is to segment the input debate case into text sections that correspond to unique different arguments in the case. This, in itself, can be a challenging problem depending on the input case text formatting.
As a first approximation, it makes sense to cheat and assume the argument text input into the system is already chunked up into different unique arguments. Paragraph structure in the case text could be used to chunk the case into unique arguments.
More advanced text segmentation and summarization approaches can be used to find key arguments. For instance, the use of Named Entity Recognition and sentence level scoring can help find important sentences in a corpus. An even more advanced approach would be to use text semantic similarity and cohesion to cluster text into arguments based on vector cosine similarities.
I have yet to see natural language processing that really optimizes the type of semantics that debate really cares about. A fairly nifty thing to try would be to try to fingerprint claim-warrant-impact classifications in a K-Nearest-Neighbor space. Underlying argumentation, this type of structure is really what is prevalent (and known in debate for some time). We need to get a natural language processing classifier to the level where it can semantically reason about claims, warrants, and impacts rather then just simple text features. Fingerprinting these things would be useful since text blobs with the same semantic fingerprint in this space would correspond to the same functional underlying argument. Learning this kind of decomposition would be helpful, and I suggest fingerprinting methods because I’ve had success with these in other domains.
Once the case is dissected into arguments, we can run a machine learned argument classifier to determine which argument it is (from a stored database of known arguments).
Argument Classifier
The design of the argument classifier is very interesting because it brings up interesting philosophical questions. What makes arguments unique from one another? Is it possible to delineate a set of unique arguments for a particular side of a topic? I don’t have good answers to these questions, but one can use Machine Learning to see if it’s possible and how well we can do.
Imagine we have a large data set of debate cases on a particular side of a single topic. For example, LDDebate.org used to contain hundreds of cases on a single topic. You can still visit it today on the Internet Archives (http://web.archive.org/web/20031211055027/http://www.lddebate.org/?go=caseExchange). However, the site has been largely defunct for the last decade or so, and the Internet archive did not save any of the dynamic forum pages containing the cases. Thus, unfortunately, a data set from here cannot be assembled. But a data set could be assembled from somewhere. The data set I have assembled right now is a relatively small data set from my time critiquing novice cases at Monta Vista High School. Maybe a large team would be kind enough to give me an expansive data set on an old topic.
There does likely exist some significant regularity in most debate cases at a semantic argument level. A large portion of the human debate population runs the same general (“stock”) arguments at a debate tournament. Arguments are made with linguistic variation, but regularity exists at a higher semantic level by a couple of principal components of argumentation. This is the principle by which “blocks” are effective because if regularity did not exist, there would not be any point in doing these. It is thus important to attempt to identify this type of regularity in the arguments buried in all the rest of the linguistic “noise” in the data set.
A starter approach would be to run unsupervised topic modeling to understand what are the key arguments in the set of cases. However, this approach suffers from being mostly based on word features whereas what we care here is about semantic regularity. Semantic feature analysis techniques based on Penn Tree Bank or WordNet ontologies could be used to augment word features to improve classification and modeling of linguistic variation. This has been known to help summarization algorithms.
Since Natural Language Processing methods can be challenging, I’m inclined to suggest really supervising the process. At the moment, humans are the best at identifying this regularity so it might make sense to crowd-source the problem and have human annotators clump the text from cases into fundamentally different arguments and train a bag or words (or potentially more powerful) model. Co-training with different word synonyms could help too.
Once an argument classifier is built from data, we could classify new segments of text into appropriate categories of known arguments. The argument classifier could be used to take a case dissection and produce a list of recognized argument_ids in the case drawn from its database.
Feasible Response Knowledgebase
The robot also contains a knowledgebase that maps recognized arguments à feasible responses. A “recognized argument” is an argument id of a unique argument in the knowledgebase. A feasible response is a tuple(T,U) where T is the text of the response and U is the estimated utility of making that response (in relation to other responses for that argument).
The knowledge base emulates how human debaters have “blocks” against common arguments. The feasible responses could be unique responses. They could also be the same response but of different text lengths so that the later scheduling algorithm can be smart in deciding how to schedule arguments based on the time limit.
The utility score attached to the text response emulates how humans often place priorities on responses on their blocks. It also serves as the input to the strategy engine, which can use this information effectively.
How should the knowledge base be populated? I’m inclined to cheat and just have human annotators populate the knowledgebase. You could try to learn this data too from lots of video/audio transcriptions of debate rounds on the same topic. The blue-sky idea would be to have the utilities credit-assigned based on transcripted judge critiques, but my guess is the data to train such models well does not exist…yet. When online debate really takes off, “hello world.”
Strategy Engine
The design of the strategy engine brings up a lot of thorny issues. Obviously there is the really thorny question of to what extent debate should even be viewed as a game, and the laundry list of implications in doing so.
In designing this debate robot, my perspective is not to be interested in these philosophical questions at all. I think an appropriate stance is to sidestep all these normative questions and just realize that descriptively debate can be computationally modeled as game for the purposes of engineering design.
As a scientific description, the game theoretical viewpoint allows us to quantify rigorously the effects of different strategies. As a computational model, this view provides us a rigorous and increasingly well-studied quantitative tradition to which to ground our response generation in. From the perspective of trying to build a debate robot, the viewpoint allows us to come up with functional algorithms. As an engineer, I want my robot to work at some minimum level. Game theory is the only promising framework available to engineers to achieve somewhat human-esque strategy generation.
Grounding our strategy engine in game theory does introduce computational considerations since parts of game theory can be solved well, whereas other parts are, without problem specific semantics, wildly intractable. A naïve starter approach might be to try to encode utilities in a zero sum game, a type of game in game theory that can be solved efficiently using a linear program.
I think a fairly interesting result is that debate is actually a very depth-limited game. Unlike chess which can go on to hundreds of moves that an agent playing the game has to reason over, a debater really only has to reason to depth 4 or 5 since there are a very few number of speeches. Each speech allows debaters to make an argument / move and the important thing is to have a good move by the type the final rebuttals come around. Thus, my thought is that a fairly decent model would be use a game tree and solve via backwards induction. Debate is a fairly tractable game!
The strategy generator would be able to assign utilities for particular arguments in relation to what the opponent might do. Reasoning over possible responses to responses, the robot would be able to score each of the feasible responses as helping maximize its strategy to win the round or not and to what degree.
The output of the strategy generator is thus a strategy score for each of the feasible responses. These strategy scores are then used by our scheduling algorithm to decide what arguments should be made by the debate robot and when.
Response Scheduling Algorithm
The response-scheduling algorithm facilitates decision making of which of the feasible arguments to incorporate into the speech and when is the optimal time in the rebuttal for making particular arguments. The response scheduler uses the scores of the strategy engine on the feasible responses to choose a subset of responses to schedule.
One useful and very powerful model from job scheduling is the Weighted Interval Scheduling problem. The Weighted Interval Scheduling problem takes as input a set of jobs parameterized by (S,E,U) where S is the start time of the job, and E is the end time of the job, and U is the job’s utility. Different jobs may overlap. An algorithm that solves the Weighted Interval Scheduling algorithm finds the set of non-overlapping jobs (from the input) that maximize the sum of utilities.
Intriguingly, the Weighted Interval Scheduling problem has a dynamic programming solution that runs in O(nlogn). This algorithm provides an efficient solution to the general computational problem of scheduling jobs parameterized by start and end times and utility. We can use the algorithm to build a response scheduler for our debate robot. The utilities from the strategy generator for feasible arguments could be used to test different scheduling of arguments efficiently.
Given possible scheduling of arguments, the Weighted Interval Scheduling algorithm can help us find the responses to use in the speech that fit the speech time limit and help maximize the chance of winning the round (by taking into account the strategy scores). It can additionally take into account constraints of argument ordering for persuasion emphasis. Different orderings of arguments can be proposed to the Weighted Interval Scheduling algorithm and it will help find the optimal ordering!
The Weighted Interval Scheduling algorithm can help schedule which responses to make in the round. Based on the response list, a debate speech can be generated based on the scheduled text. The text could then be piped to a text-to-speech engine for all hear to the debate.
III. Conclusion
Obviously, the biggest question of this design is: Can this crazy somewhat hacked together contraption work at all?
Chances are, if put together well, it might be able to debate a canned round in a fairly minimalist sense. Obviously, there are an insane number of simplifications and hacks. There are also an insane number of failure cases. This debate robot would have no chance against arguments it had not heard before, would not be able to adapt in any way to judges, etc.
Perhaps the greatest current shortcoming is it does not take into account the most important constraint: attempting to convince a human judge about the merits of arguments! We would need to have reliable brain computer interfaces and neural population decoding to really understand and mine judges’ brains! Well, maybe.
The contribution of this article is to try to take something that has never been formulated in an engineering perspective, never been tackled via a highly rigorous scientific perspective, and formalize the components with the hopes of eventually building a working system. Nobody has really even thought to put the pieces together to build these kinds of things.
You decide: Is this type of system in any way possible?
The goal of guitar stylometric analysis is to understand what a user might be playing on a guitar and characterize how they might be playing it. Standard sheet music is a very limited way to convey musical ideas. If you give two people the same sheet of music, chances are they will play it slightly differently. Everyone has their own artistic flair.
Everything that an artist is doing on an instrument (in terms of end-effectuation) can likely be sensed on the guitar and modeled by the principles of computer science and engineering. Whether we have the appropriate sensing capabilities to build appropriate classification is debatable. Can such artistic fluctuations can be captured and appropriately modeled?
The goal of my latest hack project is to try to build a Robotic sensing architecture and system for guitar that could be used to capture stylistic playing effects and understand them using scientific and engineering lenses. To make the system widely usable, it is built with only widely available consumer electronic devices without requiring special hardware. Thus far, I have experimented with two sensing modalities:
Use of smartphone (with accelerometer) mounted on guitar body to detect vibration patterns near guitar strings
Use of smart watch on user’s wrist to capture guitar strumming patterns.
Note I haven’t done machine learning yet on this data, and have mostly just applied standard signal processing techniques to it. I have just started building the platform and have yet to collect that much data. Once I get more data, I think I will be able to build more intricate computational models and do some cooler stuff applying large scale ML personalization work to this. My goal is to the apply the Lunar Tabs Machine Learning engine to such a collected data set. See this working paper for building high-dimensional, intricate (but computationally efficient) music personalization models:
Though the paper is written for guitar learning and difficulty analysis, the underlying Active Learning methods are powerful and expected to scale to the high-dimensional feature space of artistic perception and find the major features explaining artistic variation. Building these very intricate models of artistic variation is the eventual goal of the project.
However, I am first starting by building a good sensing platform to collect the right data for use in such models. It is neat what a couple of well-placed sensors on the guitar and user can do to get data set of explanatory guitar playing data.
Smart Phone mounted on Guitar
A smartphone (with accelerometer) mounted on the guitar can be used to capture vibration patterns on the guitar surface. Such a sensing modality can readily capture playing effects such as vibrato, percussive effects, and more. See figure below for setup.
My guitar has both a mounted mobile phone and a hexaphonic pickup. The mobile phone provides vibration pattern data while the hexaphonic pickup provides midi. Both can be used to characterize what the user is playing in real-time. Both are also held together shamelessly by tape which is an engineer’s best friend (don’t try this at home just yet).
Here are some of the effects we can detect with the mounted hardware.
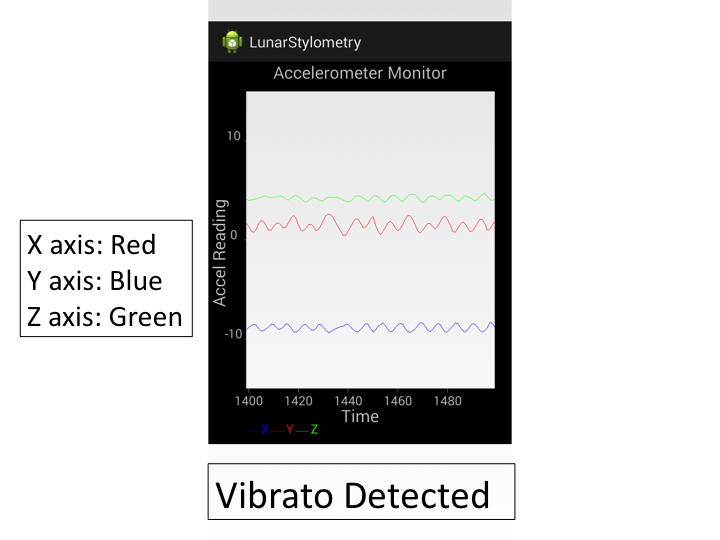
Detecting Vibrato
Vibrato is a musical effect consisting of regular, pulsating change of pitch. Vibrato is characterized by periodicity in the accelerometer signal that can be identified using frequency domain analysis.
This is a counter-intuitive statement but…
It can actually be easier to detect vibrato from motion than audio. Since audio is often distorted by guitar electronic noise and other junk, it might take a bit more work to extract the raw signal that you’re looking for that you could get straight from the vibration source.
Using a Fast Fourier Transform (FFT) package, it was fairly straight-forward to (1) Run FFT on the accelerometer axes and (2) Threshold on magnitude of power of the real component to detect the presence of vibrato in real-time.
There is the the problem of false positives — a person might shake the guitar and it would still produce a periodic signal on the accelerometer. To counter this, a set of empirical thresholds for the algorithm can be chosen using Receiver Operating Characteristic (ROC) curve analysis to find the right set of thresholds to maximize the probability of dismissing the false positives. Vibrato has a particular frequency band that we can leverage.
Detecting Percussive Effects
Percussive guitar is a genre gaining in popularity. Pioneered by artists like Tommy Emmanuel (and some fairly cool you tube videos), percussive guitar players take advantage of tapping and other effects on the body of the guitar to produce percussion-like sounds.
Percussive effects can be readily detected by accelerometer vibration patterns on the guitar surface. The simplest ones are spikes that can processed using a band-pass filter. However, detection of signal can likely be boosted with Machine Learning techniques like PCA that can build a good shape model for different types of spikes. If you really want to get intricate in building signal models, see my thesis work (which I am still working on).
Aligning with Midi
Note that my guitar set-up screen shot showed a mounted Fishman Triple Play (http://www.fishman.com/tripleplay/details). Hexaphonic pickups such as these provide the capability to convert a standard analog guitar into midi. These products allow detection in real-time of what notes/chords the user is playing, conversion to midi, and then streaming over bluetooth to a usb receiver.
Midi is very very useful because it tells you very precisely what the user played in terms of a stream of time-stamped notes. Notes close together in a midi stream are clumped into chords. You could try to figure out what the user is playing in standard audio signal processing, but it’s messy and less accurate. Hexaphonic pickups greatly simplify the signal-processing problem in my experience. I highly recommend them since they’ve made my life so much easier.
Time-aligning the midi and detected vibration effects can help build a pretty intricate profile of what notes the user played and how they were played. Imagine using this system to capture artistic style from your favorite artist so you can have a make a better cover. Perhaps you could develop your own too and share your “style” with the world more quantitively in some type of multi-modal tab. Possibilities yet to be explored.
Detecting Strum Patterns using Smart Watch
The latest smart watches come with accelerometers, and the engineering challenge is to figure out what to do with them.
One use case I am working with is to use a smart watch to track a person as they are strumming the guitar. There is certainly application to online guitar learning. If a person’s strumming can detected, an application could help instruct whether an appropriate up/down stroke was made at the right time in playing a particular piece. I tend to mess up strum patterns but an intelligent app could tell me when I’m flubbing things up.
I have data collected from a Pebble smartwatch while I wait for other smart watches to come out. Here is my pebble (complete with a flappy bird app!)
Why did I choose to get a Pebble with the upcoming Android Wear and IOS smartwatches? Well, for Robotic enthusiasts like me, it’s really important to get actual representative sensor data to play with. Actual hardware and actual sensor always beats building stuff in idealistic simulation. If you want to get stuff to work in the real world it better well match statistical distributions of actual sensor data.
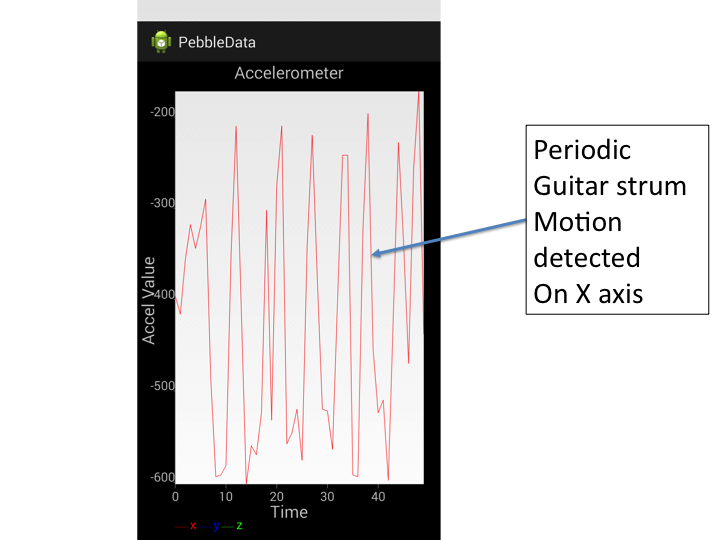
Standard chord guitar strumming produces a periodic vibration pattern that one should readily be able to apply FFT approaches to.
The data is very clean and very periodic. Up/down strokes on the guitar are very well tracked by the smart watches accelerometer. Each of the ups and downs of the signal corresponds to an up or down strum with my pick on the guitar.
I believe it is possible to capture plenty of diverse strum patterns in computational models of smartwatch accelerometer data. Different strum patterns and patterns at different tempos will have a unique time series profile that can be fingerprinted. Imagine a guitar app that actually helps you train your strumming.
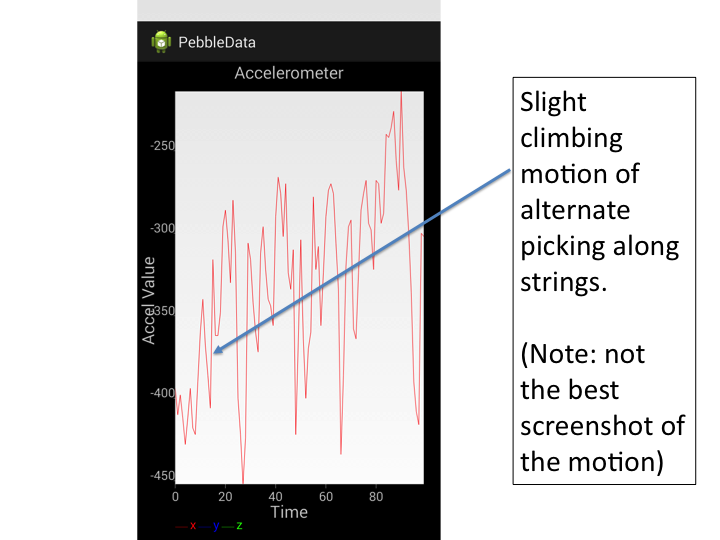
An even more interesting thing that can be seen in the data is with alternate picking.
Interestingly, the accelerometer signal is still roughly periodic but has a linear component that corresponds with the vertical displacement of the user’s hand. This information could be used by an intelligent guitar teacher (or app) to help a student improve picking technique (since that can be a challenging thing to learn).
Next Steps
I would like to use this platform to collect data, and further improve the detection techniques for stylistic effects. I think there’s also neat things that could be done with fusing the different sensed modalities that haven’t been explored yet.
Also, I believe there is a lot that can be done with Machine Learning on this data to understand individual artistic nuances in playing guitar and for effective learning of different musical styles. Modeling stylistic effects actuation on instruments can help us better understand our musical capabilities.
And of course, the real (implicit) goal of this is to understand better how humans actuate music to allow Strong AI robotic agents to transcend human capability at creating music and art…
Lunar Tabs, an accessible guitar tab reader that the Project:Possibility team has been hard at work on has been receiving a lot of publicity recently. Thanks to all for promoting our cause! We are hard at work on the journal paper and are testing different beta versions of the app.