I. Human Subtraction Paradigm
The dominant trend in many Robotics and Machine Learning problems is to view the humans as the source of signals to be detected and localized, while the environment is the noise to be removed from the signal. Camera-based localization of pedestrians and tracking of the elderly indoors using range sensors are examples. Human Subtraction is a new paradigm in Robotic Learning where the goal is to filter out humans from the data rather then the background.
Humans are known to corrupt data (such as air data with pollution, water data with oil, night sky with light, etc) that often needs to be denoised of such human intervention. Human Subtraction is useful when a robot, agent, or cyborg needs to filter out pesky corruption (caused by humans) on data to recover an original state of nature of that data.
II. Barometric Altitude Estimation Domain
The general problem of indoor altitude estimation is to determine the altitude of a person inside a building. In this study, we develop Human Subtraction algorithms for smart-phone barometers to account for weather drift effects in estimating altitude with large amounts of sensor data.
Many smart-phones now come with built-in barometer sensors that measure external atmospheric pressure in millibars (mBar). Using a simple conversion formula between the smart phone barometer readings and altitude (m), it is possible to estimate a person’s altitude indoors with a typical error tolerance of +/- 1m. Atmospheric pressure, however, drifts over time due to external changes in weather conditions, temperature, etc. This means that the expected barometer reading for a particular indoor altitude changes as weather changes. The same indoor location may register as up or down several millibars in barometer reading after a couple hours. The Robotics/Machine Learning challenge is to correct for this weather drift by estimating it and subtracting it out from the data.
One way of accounting for weather drift is to estimate the drift using another proximal barometer sensor such as a weather station. The idea is that if two sensors geographically close by that are observing the same external weather conditions, they will correlate in the weather drift they measure. Thus, the drift from the second sensor can be used to account for the (unseen) drift in the first sensor. This approach has been shown to well in practice with weather stations (Tandon 2013).
The limitation of this approach, however, is the need for an additional sensor and a communication link between the devices. Having to query a weather station requires Internet connectivity, which may not always be available (or only sporadically available) in indoor locations or underground. In addition, weather stations typically only report readings every couple of hours, which may limit their effectiveness in correcting for drift effects. For example, during a thunderstorm, drift may affect the data much more quickly than the granularity provided by weather station APIs.
In this paper, we tackle the problem of developing a method of estimating an environment’s temporal atmospheric drift using just a single barometer sensor. We believe this problem is solvable using a Human Subtraction approach with no additional external hardware. We believe is it possible to remove most of the human effects from the data.
III. Application of Human Subtraction Approach to Barometer Domain
If a barometer sensor is stationary, it mostly only observes the environment drift. When humans move with a barometer sensor, they introduce altitude movement noise into the observation of the environment drift. One can think of the barometer signal observed of a sensor carried by a human as an additive combination of two signals: the underlying environmental drift and the contribution due to the altitude motion of the human (up/down stairs, elevators, slopes, etc). The principle of Human Subtraction in the barometer domain is to subtract out the effects of the human altitude motion, leaving only the original environmental drift intact.
Two general scientific/statistical principles come in play in the development of a sensor data processing method to recover environment drift using only a single barometer sensor.
First, observed atmospheric pressure changes due to human altitude motion often occur much more quickly than environment drift. For instance, a human climbing upstairs or taking an elevator causes faster change in observed atmospheric pressure by a barometer than what the natural weather drift causes. The derivative of the barometer time series thus has substantial information. By filtering the derivative for large changes, we can remove many effects of human motion from the data.
Second, environmental drift is something that becomes prevalent overtime whereas human interaction tends to be instantaneous. By viewing the data under multiple resolutions of time binning, an algorithm can gain a better estimate of the drift then by viewing it under only one granularity. The mode of the data under a coarse-binned barometer data stream is particularly informative. Human motion tends to change the data a lot. For example, a human moving up an elevator is never at the same altitude for two time points. However, if a measurement is just affected by environmental drift, the readings tend to cluster around a single value. Thus, taking the mode of the distribution gives the most common value in the distribution, which is more likely to belong to the environmental drift component than the human motion component.
The developed algorithm, thus, involves the following steps of processing:
- Preprocess data: Remove global outliers in time using k-sigma filtering. This removes major sensor noise from the data (caused by slamming of the phone by the human and other malfunctions of the sensor). Also, interpolate for missing data time points where the phone may have been turned off.
- Bin the barometer data using a fine resolution in time (i.e. 2-3 seconds) so that motion effects of the human can be filtered.
- Filter the derivative of the signal by thresholding on the maximum margin of environment contribution vs. human contribution to the barometer signal.
- After motion filtering, rebin the data using a coarse resolution in time (i.e. 30 seconds – 1 minute) to account for long time-scale effects in the data.
- On the coarse-binned data, smooth the data using the mode of the distribution in each time bin. Find the time point closest to the mode in each bin.
- Linearly interpolate between consecutive characteristic mode points between bins to create the final robust estimate of environmental drift.
IV. Experiments and Results
Barometer data was collected using two Android smartphones for six days. One phone remained stationary for the data collection period on a desk. The other phone was carried through an operator’s daily activities. We treat the stationary sensor as the source of ground truth for environmental drift. We apply the Human Subtraction algorithm on the phone carried by the operator and plot the results.
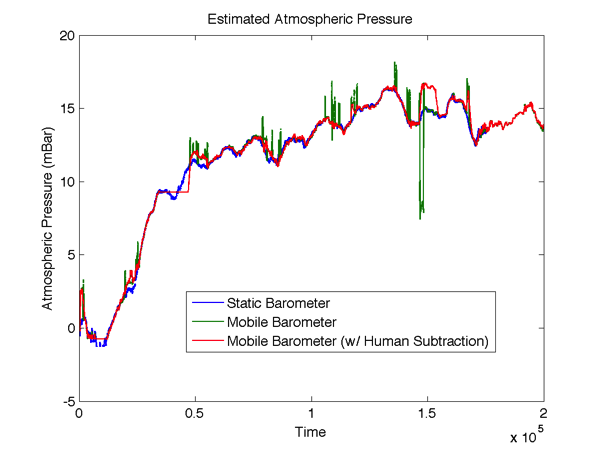
Figure 1 plots the estimated atmospheric pressure for the static barometer and the mobile barometer with and without Human Subtraction. Using the Human Subtraction approach, we achieved a significant reduction (from not filtering the data) in sum of squared error of about 65%! We can recover much of the environmental drift, while removing the human motion effects from the barometer data stream.
One can also view the Error CDF of the Human Subtraction algorithm in Figure 2. After the tolerance of the barometer (+/- 1 mBar), the Human Subtraction algorithm quickly suppresses large errors in mBar (due to human motion) that the barometer (without filtering) is susceptible to.

In terms of estimated altitude error, 1 mBar = 8.5m. Thus, the worst error of the Human Subtraction algorithm is much less than the worst error of the unfiltered data. The worst error of the filtered approach levels off at 2 mBar whereas the worst error of the unfiltered data levels off at 6 mBar.





 T
T